Most of the time data loading isn’t something we think about when doing public data analysis. Datasets such as nflfastR aren’t that large in the grand scheme of things. But what if you’re looking to compete in the next big data bowl? Or what if you just need certain portions of nflfastR?
This walkthrough inspired by this NYR post: https://enpiar.com/talks/nyr-2020/#19
And Thomas Mock from the Rstudio team: https://gist.github.com/jthomasmock/b8a1c6e90a199cf72c6c888bd899e84e
library(tidyverse)
library(arrow)Well, we can read in our data more efficiently to save ourselfs not only time but also RAM by not storing huge datasets in memory.
In order to run the arrow package as I have here, you will need the nightly build. See the above nyR post for details.
First, let’s take a look at how fast we can pull down the latest pbp data from nflfastR.
seasons <- 2010:2019
system.time(
pbp <-
purrr::map_df(seasons, function(x) {
readr::read_csv(
glue::glue("https://raw.githubusercontent.com/guga31bb/nflfastR-data/master/data/play_by_play_{x}.csv.gz")
)
})
)
user system elapsed
41.53 13.61 69.14 Your results may vary here, but for me? This process usually takes 30-45 seconds. Now, if you’re easily distracted like I am that’s just enough waiting around to be dangerous!
Of course the alternative is to simply read in the data from a local copy, which is of course faster. We’ll use data.table’s fread here as it’s much faster than both the base read.csv and tidyverse’s read_csv.
system.time(pbp <- data.table::fread("D:/Placeholder/nflfastR.csv"))
user system elapsed
7.38 0.53 2.98 But what if we could do better? Or, what if we needed to load in much MUCH larger files? Perhaps gigabytes each? And what if we wanted to find a way to do some filtering as well?
Enter the arrow package.
Arrow is a C++ backend that works across multiple languages to allow you incredibly fast load times and lets you conduct some of you first steps on disk. Meaning you’re not pulling the entire file into memory first.
First we need to convert our data.frame into an arrow table. I found that using uncompressed made the process much faster.
write_feather(pbp, "D:/Placeholder/New/new_file", compression = "uncompressed")
ds <- open_dataset("D:/Placeholder/New/", format = "feather")
system.time(open_dataset("D:/Placeholder/New/", format = "feather") %>% collect())
user system elapsed
2.14 3.04 2.14 We can see that arrow loads our dataset pretty fast. A little faster than fread, but what if we could make it better?
Lets say I wanted to partitian the data by both season and play type. We can do this by converting our feather file to a dataset. We should choose ways to split the data that make the most sense given our usecase. For football, it may make sense to break things down by season and playtype since those are common splits to look at.
feather_dir <- "D:/nflfastR/"
ds %>%
group_by(season, play_type) %>%
write_dataset(feather_dir, format = "feather")Now for our last step, direct comparison!
For each test I am going to open a file, filter down to a particular season, play_type, then perform some summaries.
system.time(
data.table::fread("D:/Placeholder/nflfastR.csv") %>%
filter(season == 2019, play_type == "pass") %>%
group_by(posteam) %>%
summarise(epa = mean(epa, na.rm = TRUE))
)
user system elapsed
7.63 0.50 3.13 Notice below that I am using the collect() call between group_by and summarise!
system.time(
open_dataset("D:/nflfastR/", format = "feather") %>%
filter(season == 2019, play_type == "pass") %>%
group_by(posteam) %>%
collect() %>%
summarise(epa = mean(epa, na.rm = TRUE))
)
user system elapsed
0.25 0.05 0.29 There you have it, to read in, filter, group, and summarise from data.table’s fread takes us significantly longer to read in than using arrow’s feather data type!
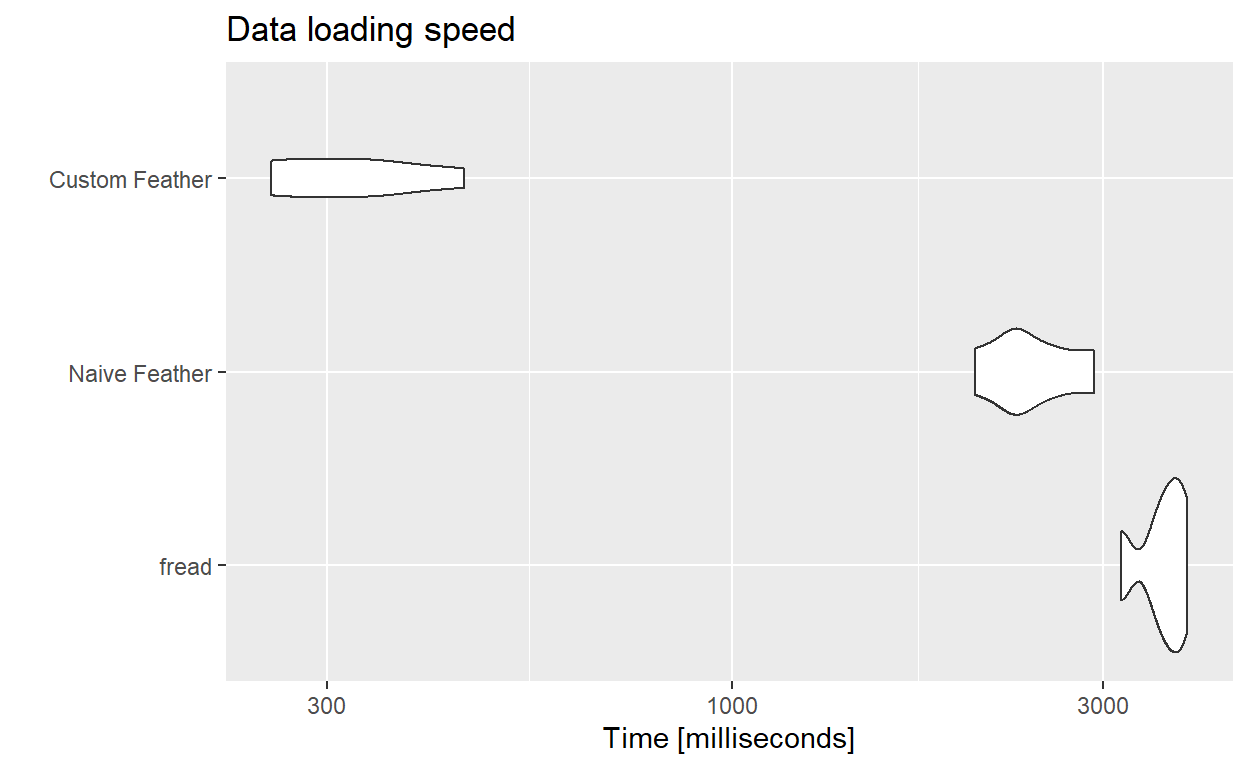
We’ve gone from loading online in about 60 seconds, to fread in 3-5 seconds, to feather around 2 seconds, but by saving our dataset in a novel way we can reduce our look ups to fractions of a second.
This 10x speed up might seem not worth the effort for this one file, but as these files get larger, as you merge more sources, these techniques can save a lot of time.
mbm <-
microbenchmark::microbenchmark(
"fread" = {
data.table::fread("D:/Placeholder/nflfastR.csv") %>%
filter(season == 2019, play_type == "pass") %>%
group_by(posteam) %>%
summarise(epa = mean(epa, na.rm = TRUE))
},
"Naive Feather" = {
open_dataset("D:/Placeholder/New/", format = "feather") %>%
collect() %>%
filter(season == 2019, play_type == "pass") %>%
group_by(posteam) %>%
summarise(epa = mean(epa, na.rm = TRUE))
},
"Custom Feather" = {
open_dataset("D:/nflfastR/", format = "feather") %>%
filter(season == 2019, play_type == "pass") %>%
group_by(posteam) %>%
collect() %>%
summarise(epa = mean(epa, na.rm = TRUE))
},
times = 5L
)Here is a plot showing the loading times for various methods.
autoplot(mbm) +
labs(title = "Data loading speed")